이전에 이 글에서 JPA를 다뤘었습니다. Spring Boot에서의 JPA사용은 그 때의 JPA사용과는 다를 수 있습니다. 왜냐하면 JPA의 동작을 좀더 자세하게 알고자 EntityManager를 이용해 수동적으로 Transaction을 다뤘기 때문입니다. 그러나 Spring에서 JPA를 종더 편리하게 사용하고자 Spring Data JPA를 만들었습니다. 이 Spring Data JPA를 사용한다면 일련의 과정들을 자동으로 처리해주기 때문에 더욱 편리한 사용을 할 수 있습니다. 이번 시간에는 Spring Data JPA에 대해 알아보도록 하겠습니다.
1.Spring Data JPA
Spring Data JPA의 핵심은 Repository에 있습니다. 아래의 그림을 보겠습니다.
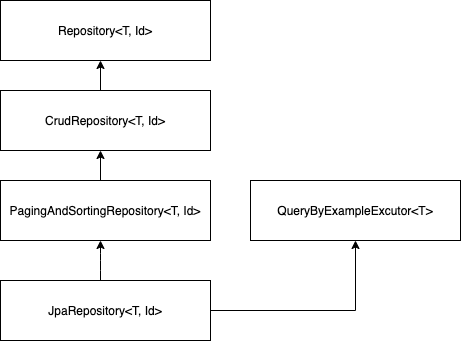
Repository는 Spring Data Interface의 중앙 저장소 역할을 합니다. T는 엔터티의 클래스 유형이고, Id는 @Id의 타입입니다. 아래는 CrudRepository의 모습입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
@NoRepositoryBean
public interface CrudRepository<T, ID> extends Repository<T, ID> {
<S extends T> S save(S var1);
<S extends T> Iterable<S> saveAll(Iterable<S> var1);
Optional<T> findById(ID var1);
boolean existsById(ID var1);
Iterable<T> findAll();
Iterable<T> findAllById(Iterable<ID> var1);
long count();
void deleteById(ID var1);
void delete(T var1);
void deleteAll(Iterable<? extends T> var1);
void deleteAll();
}
CrudRepository를 살펴보면 우리가 구현해야될 쿼리들이 기본적으로 구현이 되어 있습니다. 잠시 살펴보겠습니다.
1) save : 주어진 엔터티를 저장합니다.
2) findById : 주어진 Id로 식별된 엔터티를 리턴합니다.
3) findAll : 모든 엔터티를 반환합니다.
4) count : 엔터티의 수를 반환합니다.
5) delete : 주어진 엔터티를 삭제합니다.
6) existById : 주어진 Id를 가진 엔터티가 존재하는지 여부를 나타냅니다.
우리가 일반적으로 구현해야할 쿼리들이 미리 만들어져 있기 때문에 단지 Repository에 구현된 메소드를 사용하기만 하면됩니다. 그럼 간단한 실습을 통해 Spring Data JPA에 대해 더 알아보겠습니다.
2. 실습하기
먼저 실습환경에 대해 말씀드리겠습니다.
- Spring Boot2.2.4.RELEASE
- Maven
- Oracle(DB)
Oracle을 사용한 이유는 H2만 사용하다보니 사용하고 싶었습니다… 다른 데이터베이스를 사용하셔도 상관없습니다.
Maven Dependency
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>com.oracle</groupId>
<artifactId>ojdbc6</artifactId>
</dependency>
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
의존성은 먼저 Oracle데이터베이스와 HikariCP를 추가 했습니다. HikariCP는 커넥션풀의 설정을 도와주는 역할을 합니다. 그 다음 Spring data jpa와 lombok을 추가 했습니다.
applicaion.properties
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# Oracle settings
spring.datasource.url=jdbc:oracle:thin:@localhost:1521:xe
spring.datasource.username=JPA_TEST
spring.datasource.password=a1234
spring.datasource.driver-class-name=oracle.jdbc.driver.OracleDriver
spring.jpa.show-sql=true
# Hikari CP settings
spring.datasource.hikari.connection-timeout=600000
spring.datasource.hikari.maximum-pool-size=5
# logging
logging.pattern.console=%d{yyyy-MM-dd HH:mm:ss} %-5level %logger{36} - %msg%n
logging.level.org.hibernate.SQL=debug
#logging.level.org.hibernate.type.descriptor.sql=trace
logging.level.=error
# Server port
server.port=8081
#Oracle settings에서 Oracle 데이터베이스와 관련된 설정을 해줍니다. 서버포트를 변경한 것은 Oracle이 8080포트를 사용하고 있기 때문에 변경해 줬습니다.
그 다음 Oracle에 Table과 Sequence를 생성해 줬습니다.
CREATE TABLE MEMBER(
id NUMBER PRIMARY KEY,
NAME VARCHAR2(255),
EMAIL VARCHAR2(255),
UPDATE_TIME TIMESTAMP
);
CREATE SEQUENCE MEMBER_SEQ
START WITH 1
INCREMENT BY 1
NOCYCLE
NOCACHE;
그 다음 Member 엔터티를 생성해 줍니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
@Entity
@Getter @Setter @ToString
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "MEM_SEQ")
@SequenceGenerator(sequenceName = "MEMBER_SEQ", allocationSize = 1, name = "MEM_SEQ")
private Long id;
private String name;
private String email;
private LocalDateTime updateTime;
public Member(){
if(StringUtils.isEmpty(updateTime)){
this.updateTime = LocalDateTime.now();
}
}
}
@Id밑에 있는 @GeneratedValue와 @SequenceGenerator를 이용해서 Oracle의 시퀀스와 매핑해줬습니다. updateTime을 보시면 테이블의 UPDATE_TIME과 이름이 다른 것을 보실 수 있습니다. 그 이유는 Entity에서 Camel Case로 작성하게 되면 Default가 ‘_‘로 합쳐진 형태의 컬럼명과 매핑을 시도하게 됩니다.
마지막으로 Repository를 생성해 보겠습니다.
1
2
3
public interface MemberRepository extends JpaRepository<Member, Long> {
}
아무것도 구현하지 않고 JpaRepository를 상속받기만 한 상태입니다. 이제 테스트를 해보겠습니다. 먼저 데이터베이스에 저장하는 테스트를 진행해 보겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
@SpringBootTest
class MemberRepositoryTest {
@Autowired
MemberRepository memberRepository;
@Test
@DisplayName("Member 저장")
void memberSaveTest(){
Member member = new Member();
member.setName("jongmin");
member.setEmail("test@test.com");
Member member1 = memberRepository.save(member);
assertEquals("jongmin", member1.getName());
}
}
테스트를 실행하면 데이터베이스에 값이 들어간 것을 확인하실 수 있습니다. 또한 save후 Member엔터티로 리턴을 받아 기존의 값과 비교를 진행합니다. 그 이유는 save후 저장한 객체를 리턴해주기 때문에 비교를 진행한 것 입니다. 이제 다른 테스트도 진행해 보겠습니다.
1
2
3
4
5
6
7
@Test
@DisplayName("Member 조회")
void findMemberJongminTest(){
Optional<Member> member = memberRepository.findById(1L);
assertEquals("jongmin", member.get().getName());
}
findById를 이용하여 앞에서 저장한 값을 조회하여 비교하는 테스트를 진행했습니다. findById는 기본적으로 Optional
1. 메소드 이용
MemberRepository에 다음을 추가해 보겠습니다.
1
2
3
4
5
public interface MemberRepository extends JpaRepository<Member, Long> {
Optional<Member> findByNameAndAndEmail(String name, String email);
}
여기서 값이 여러개일 경우는 List
로 구현하시면 됩니다.
이제 테스트를 진행해 보겠습니다.
1
2
3
4
5
6
7
8
9
10
@Test
@DisplayName("메소드 이용")
void findMemberByMethod(){
String name = "jongmin";
String email = "test@test.com";
Optional<Member> member = memberRepository.findByNameAndAndEmail(name, email);
assertEquals(name, member.get().getName());
assertEquals(email, member.get().getEmail());
}
딱히 다른건 구현하지 않았는데 잘 값이 출력됩니다. Spring Data JPA에서 지원해주는 강력한 기능 때문에 가능한 일입니다.
Spring Data JPA에서는 메서드 이름으로 쿼리를 직접 파생시킬수 있습니다. 접두사 스트림 find..By, read..By, query..By, count..By, get..By와 And, Or등을 조합하여 사용할 수 있습니다. 몇가지 예시를 보겠습니다.
- List
findDistinctNameById(Long id) - List
findByNameIgnoreCase(String name) - List
findByNameOrderByNameDesc(String name)
위와 같이 메소드를 이용하여 쿼리를 파생시킬 수 있습니다. Between, Like, GraterThan등 다양한 쿼리를 조합할 수 있습니다. 페이징을 할 때도 편리하게 사용가능 합니다.
- List
findTop10ByName(String name, Pageable pageable) - List
findFirstByName(String name, Sort sort)
위의 Top을 이용하여 Top and를 구현할 수 있고 First(Default: 1)를 이용하여 결과크기를 제한 할 수 있습니다. 이외에도 다양한 사용법이 있습니다.(래퍼런스를 참고해주시기 바랍니다.)
2. @Query 사용
1
2
3
4
5
6
7
8
public interface MemberRepository extends JpaRepository<Member, Long> {
Optional<Member> findByNameAndAndEmail(String name, String email);
@Query(value = "SELECT m.* FROM MEMBER m WHERE m.email = ?1", nativeQuery = true)
Optional<Member> findMemberUseEmailAddress(String email);
}
@Query 어노테이션을 사용해서 직접쿼리를 입력했습니다. 마찬가지로 테스트를 해보겠습니다.
1
2
3
4
5
6
7
8
@Test
@DisplayName("쿼리 이용")
void findMemberByEmail(){
String email = "test@test.com";
Optional<Member> member = memberRepository.findMemberUseEmailAddress(email);
assertEquals("jongmin", member.get().getName());
}
테스트 결과 쿼리가 정상 작동하는 것을 볼 수 있습니다. 둘 중에 어느 것을 쓸건지는 상황에 따라 결정해야 한다고 생각합니다. 복잡한 쿼리가 있다면 직접 작성해야 하는 경우도 있기 때문이죠.
이외에도 페이징을 하거나 트랜잭션을 다루는 것 또는 프로시져를 등록하는 것등 JPA에는 정말 많은 사용법이 있습니다. 그러나 여기서는 기초만 다뤘기 때문에 Spring Reference를 참고 하셔서 부족한 부분은 봐주시기 바랍니다. 사실 저도 공부가 더 필요한 단계라 많이 다루지 못했습니다… 추후에 공부하게 된다면 포스팅하겠습니다. 읽어주셔서 감사합니다. 잘못된 점이나 궁금한 점은 언제든 말씀해 주시면 감사하겠습니다.
전체 코드는 Github에서 확인해보실수 있습니다.
참고
- Spring Reference(https://docs.spring.io/spring-data/jpa/docs/current/reference/html/#jpa.repositories)
- Spring Guide(https://spring.io/guides/gs/accessing-data-jpa/)