관련된 글
- [JAVA] JPA(Java Persistence API)란?(1)
- [JAVA] JPA 기본설정 및 객체생성(2)
- [JAVA] JPA 어노테이션 및 트랜잭션(3)
- [JAVA] JPA 연관관계(4)
- [JAVA] JPA 영속성 컨텍스트(5)
1. ORM(Object-relational-mapping)
JPA에 앞서 먼저 ORM에 대해 알아 보겠습니다. ORM은 Object-relational-mapping(객체 관계 매핑)의 약자 입니다. 말그대로 객체를 이용하여 매핑하는 것 입니다…. 사실 어떤 건지는 알겠는데.. ~란?했을때 딱 떨어지게 말을 못하겠습니다.. 제가 부족해서 그런거겠죠?.
ORM은 애플리케이션과 데이터베이스 사이에서 객체 지향 페러다임을 이용 데이터베이스를 다룰 수 있는 프레임워크 입니다. 대중적인 언어 대부분에는 ORM 기술이 존재합니다. JPA도 ORM 기술중 하나입니다.
더 자세한 사항은 JPA를 알아보며 보겠습니다.
2. JPA(Java Persistence API)
JPA가 나온 배경은 기본 관계형 데이터베이스(RDBMS) 와 객체지향형 프로그래밍(OOP) 의 간격을 좁히기 위해 나온 자바 진영의 ORM 표준 기준 입니다.
간격을 예시를 통해 쉽게 말해보자면 프로젝트를 진행하며 Java에서 객체(Object, POJO 등..)에 집중하며 개발하기 보다 각 테이블과 테이블 간의 관계, 즉 DB에 더 집중해 개발을한다는 것을 의미 한다고 생각합니다.
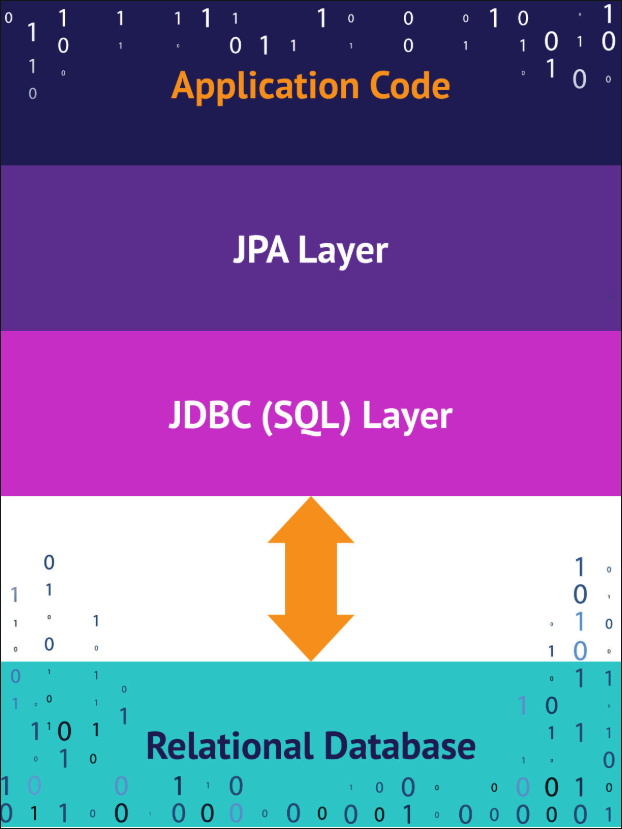
JPA는 Applicaion과 JDBC사이에서 매핑역할을 해줍니다. 매핑역할과 동시에 dialect(방언)을 처리해주는 역할도 해줍니다.
dialect(방언)
방언은 우리말로 사투리라고도 할 수 있는데요 데이터베이스는 각각이 제공하는 SQL문법과 함수가 조금씩 다릅니다. 이것들을 데이터베이스의 dialect라고 할 수 있는데 이 dialect를 JPA에서 속성을 지정하여 처리해 줍니다.spring.jpa.database-platform=org.hibernate.dialect.H2Dialectdialect의 예시
가변문자 : Mysql은 VARCHAR, Oracle은 VARCHAR2
문자열함수 : SQL표준은 SUBSTRING(), Oracle은 SUBSTR()
페이징 : Mysql은 LIMIT, Oracle은 ROWNUM
JPA를 사용하는 이유는 다음과 같은 이유들이 있습니다.
- SQL 중심개발에서 객체 중심으로 개발
- 생산성 증가
- 유지보수 용이
- 패러다임의 불일치 해결
- 성능 최적화
등이 있습니다. 위의 특징들을 앞으로 알아보도록 하겠습니다.
먼저 JPA와 RDBMS와의 차이를 보겠습니다.
3. JPA vs RDBMS
RDMS는 SQL 개발이 중심을 이룹니다. 다음과 같은 Object가 있다고 하겠습니다.
1
2
3
4
5
6
class Member{
private String id;
private String name;
private int age;
// ....
}
이 Class에 대해 RDBMS에서 다음과 같이 sql을 작성할 수 있습니다.
1
2
SELECT ID, NAME, AGE FROM MEMBER;
INSERT INTO MEMBER(id, name, age) VALUES("id", "name", "age");
여기서 Member Class에 Field가 추가 되었다고 해보면 다음과 같은 일이 벌어집니다.
1
2
3
4
5
6
class Member{
private String id;
private String name;
private int age;
private String email; // 추가된 컬럼
}
1
2
SELECT ID, NAME, AGE, EMAIL FROM MEMBER;
INSERT INTO MEMBER(id, name, age, EMAIL) VALUES("id", "name", "age", "email");
위와 같이 SQL문 하나하나에 변경사항을 입력해줘야 합니다. 지금은 Field하나, SQL문 두줄의 수정이지만 프로젝트 도중 몇십개의 테이블에 변화가 일어난다면 상상도 하기 싫은 일입니다;;
그러나 JPA의 경우 필드를 추가하면 거기서 끝입니다.ㅎㅎㅎ
이외에도 상속, 연관관계, 데이터타입, 데이터 식별방법등이 있습니다.
1) 상속
[객체 상속관계] vs [Table 슈퍼타입 서브타입 관계]
DB에서는 상속관계를 거의 사용하지 않습니다.
2) 연관관계
[객체 참조사용] vs [외래키 사용(JOIN)]
테이블의 외래키를 사용하여 JOIN할 경우 객체를 테이블에 맞추어 모델링 하는 일이 빈번하게 일어납니다. 왜냐하면 객체 답게 모델링 할 수록 매핑작업이 늘어나기 때문입니다.
예를 들어보겠습니다.
1
2
3
4
5
6
7
8
9
10
class Member{
private String name;
private int age;
private String email;
}
class Club{
private String clubName;
private String memberName;
}
위와 같은 클래스가 2개 있을 때 Mybatis를 사용한다고 하면 조인한 결과를 어떻게 가져올까요??
물론 Collection을 사용해서 가져올 수도 있습니다. 그러나 제 짧은 경험과 si에서 일할 때의 경험은 SuperClass를 만드는 경우가 빈번했습니다. SuperClass는 다음과 같습니다.
1
2
3
4
5
6
7
class MemberSuperClass{
private String name;
private int age;
private String email;
private String clubName;
private String memberName;
}
두 클래스의 필드를 모두 가지고 있는 MemberSuperClass를 이용하면 많은 매핑작업을 생략하고 값을 받아 올 수 있습니다. 위와 같은 일이 빈번하기 때문에 객체지향적인 개발과 거리가 멀어진다고 생각합니다.
물론 이렇게 말하니깐.. RDBMS가 안좋게 느껴질 수 있지만 RDBMS도 정말 중요합니다. RDBMS를 알아야 JPA도 잘 이해할 수 있기 때문입니다.
앞으로 JPA를 살펴보며 자세한 내용을 다루겠습니다.
참고
- JavaWorld (https://www.javaworld.com/article/3379043/what-is-jpa-introduction-to-the-java-persistence-api.html)
- hibernate (https://hibernate.org/orm/)
- SKplanet Academy (https://www.youtube.com/channel/UCtV98yyffjUORQRGTuLHomw)